John Cook tweeted, from his account Analysis Fact
The third of these was somewhere in my head; the first one is trivial; I had to play around a bit to find the second one. These all have in common that:
- the arguments are all whole numbers of degrees (which isn’t as arbitrary as it sounds, that’s from a set of rational multiples of π)
- the product with n terms is 1/2n.
So what’s going on here? It’s probably a bit more revealing to write the identities in terms of cosines:
cos 60° = 1/2
cos 36° cos 72° = 1/4
cos 20° cos 40° cos 80° = 1/8
as now the arguments are in geometric progression, each one double the previous. Let’s prove the third one. Recall the double angle formula sin 2x = 2 sin x cos x – from this it follows that
sin 40° sin 80° sin 160° = (2 sin 20° cos 20°) (2 sin 40° cos 40°) (2 sin 80° cos 80°)
and cancelling gives
sin 160° = 8 sin 20° cos 20° cos 40° cos 80°
Finally sin 160° = sin 20°, giving the result. Essentially this is an “octuple angle formula”
sin 8x = 8 sin x cos x cos 2x cos 4x
which is one of a family
sin 2x = 2 sin x cos x
sin 4x = 4 sin x cos x cos 2x
sin 8x = 8 sin x cos x cos 2x cos 4x
where the formula for sin 2kx can be derived by applying the double angle formula k times. Then we set x to be π/3, π/5, π/9 in order that the sines cancel; since 3, 5, and 9 are all factors of 180 these look nice in degrees. But the next entry there is π/17, giving the identity
cos π/17 cos 2π/17 cos 4π/17 cos 8π/17 = 1/16
which I won’t even bother to write in degrees. But say we take x not as π/17, but as π/15, or twelve degrees, which gives sin 16x = -sin x. Then you have
sin 192° = 16 sin 12° cos 12° cos 24° cos 48° cos 96°
and the sines cancel to leave a negative sign. That gives
-1/16 = cos 12° cos 24° cos 48° cos 96°
and taking complements yields the identity Cook gave. So it’s not exactly the next member of the family, but it’s not far off. Colin Beveridge observed that “I believe Morrie’s law is the furthest this can be taken with integer-degree angles” but this goes one further.
Historical note: The three-factor identity is known as Morrie’s law, after a boy named Morrie Jacobs, known to Richard Feynman but apparently otherwise lost to history. James Gleick had it, in his biography of Richard Feynman, that “If a boy named Morrie Jacobs told him that the cosine of 20 degrees multiplied by the cosine of 40 degrees multiplied by the cosine of 80 degrees equaled exactly one-eighth, he would remember that curiosity for the rest of his life, and he would remember that he was standing in Morrie’s father’s leather shop when he learned it.”
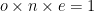
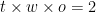


 possibilities. If we weight each of these possibilities equally, it amounts to assuming that each game is a win for A, a draw, or a loss for A with equal probability. I wouldn’t want to do this with hand, but by computer it’s easy enough. As usual, using
possibilities. If we weight each of these possibilities equally, it amounts to assuming that each game is a win for A, a draw, or a loss for A with equal probability. I wouldn’t want to do this with hand, but by computer it’s easy enough. As usual, using